Sykehusansatte kan få hjelp av nytt språkverktøy

Pasientsystemene inneholder i dag store mengder fritekst som er vanskelig tilgjengelige. Et nytt språkverktøy fra Universitetet i Agder kan lese og kategorisere slike tekstmengder på kort tid.
Språkverktøyet fra UiA har fått navnet Anzyz CCL™, og kan lese og forstå store mengder tekst uavhengig av språk.
Dette er resultatet av 10 års forskning ved Universitetet i Agder og er basert på kunstig intelligens.
Verktøyet har evnen til å lære seg et hvilket som helst språk etter å ha blitt foret med store mengder tekst.
Mannen bak programmet er professor Ole-Christoffer Granmo. Han forteller at systemet lærer seg ikke bare å forstå enkeltord, men skjønner hvordan ordene fungerer i sammenhengen og er dermed i stand til å skjønne både uttrykk og idiomer såvel som ironi, dobbeltbetydninger og ny-ord. Systemet støtter også alle alfabeter og “forstår” både dialekter og sjargong.
Medisinsk bruk
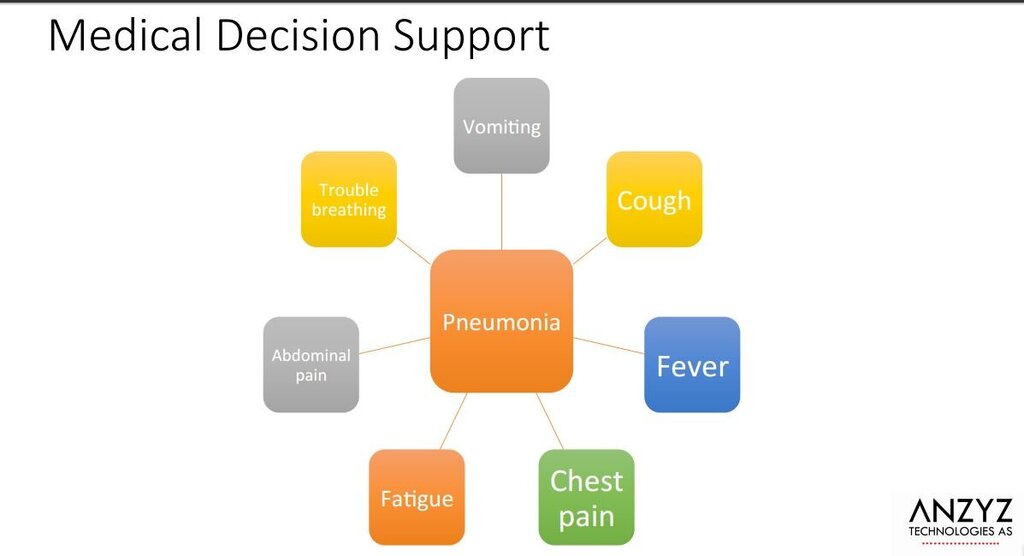
Granmo forklarer at det nye språkverktøyet kan brukes til å analysere tekst, dele opp teksten i tema og undertema og finne igjen og hente ut bestemt informasjon innenfor et stort tekstmateriale. Dessuten kan det kartlegge relasjoner og sammenhenger, for eksempel finne sammenhenger mellom sykdom og symptom.
Foreløpig kan det likevel ikke brukes til maskinoversetting.
Granmo har fått midler fra forskningsrådets program Forny 2020 til kommersialiseringen av verktøyet, og Sørlandet Sykehus er en av bedriftene som skal teste det ut.
Granmo har tro på at dette kan være nyttig til for eksempel å skaffe en rask oversikt over innholdet i tusenvis av medisinske fagartikler. Det kan ifølge ham også være nyttig om man eksempelvis leter etter sjeldne symptomer eller mulige komplikasjoner ved en bestemt behandling, eller det kan gi hjelp til å identifisere sykdommer ved å sammenholde symptomer som i utgangspunktet ikke ser innlysende ut.
Han mener også at det nye språkverktøyet kan komme til nytte i akuttsituasjoner. I sykebilen har som regel helsepersonell ikke tid til å gå gjennom store journaler, samtidig som de ofte har behov for å kjenne noe til pasientens sykehistorie, for eksempel mulige allergier. Hvis pasienten har en journal på 100 sider eller mer, så er det ikke gjort i en håndvending å hente ut den informasjonen man trenger der og da. Språkverktøyet kan for eksempel hente ut informasjonen som handler om allergi.
Strukturerer fritekst
Doktorgradsstipendiat Geir Thore Berge, som arbeider ved Sørlandet sykehus, forsker blant annet på mulig bruk av denne typen teknologi i medisinsk sammenheng. Forskningen er et samarbeid mellom Ole-Christoffer Granmo og Sørlandet Sykehus – Helse Sør-Øst under medvirkning av professor og forskningssjef Frode Gallefoss. Samarbeidet er knyttet til et pågående doktorgradsarbeid som Norges forskningsråd har bevilget midler til.
Berge forteller at teknologier som muliggjør automatisk strukturering av fritekstinformasjon i pasientjournal og avansert klinisk beslutningsstøtte nå er på vei inn i helsevesenet etter å ha vært brukt i andre sammenhenger en stund.
- Helsevesenet har særlige behov knyttet til eksempelvis pasientsikkerhet, og det er viktig å få avklart om slike teknologier vil være av verdi i arbeidsprosesser knyttet til pasientbehandling, mener han.
Et stort behov
Helse-Norge har i følge ham enorme mengder med fritekst-basert informasjon i sine pasientsystem. I forhold til total mengde informasjon som produseres i sykehusene, er kun en liten andel strukturerte data.
- Frem til nå har det vært vanskelig å bruke denne fritekstinformasjonen effektivt eller fornuftig i medisinsk sammenheng, forteller doktorgradskandidaten fra Sørlandet Sykehus.

Det dreier seg om store mengder medisinske data som er pakket inn i mange ulike formater, som skannede journaldokumenter, blanketter, skjemaer og pdf-dokumenter som ikke kan prosesseres eller søkes gjennom på samme måte som strukturerte data.
Slik dokumentasjon kan ifølge ham i en del tilfeller inneholde informasjon som kan ha stor betydning for fremtidig pasientbehandling.
- I verste fall kan slik informasjon drukne i en stor mengde annen informasjon, og dermed ikke nå frem til helsepersonell som skal behandle pasienter, påpeker han.
Agder-forskeren forteller at det han skal være med å gjøre i forskningsprosjektet er å trekke ut fritekstdata fra pasientsystemet som skal analyseres videre med CCL (Corpus Cube Linguistic) språkverktøyet.
Prosjektet har flere delmål og ett av disse er å vurdere hvorvidt teknologien kan benyttes i sammenheng med utviklingen av et klinisk beslutningsstøttesystem for helsepersonell hvor man skal kunne søke etter medisinske data av betydning for pasientbehandlingen.
redaksjonen@sykepleien.no
Mest lest








0 Kommentarer